



Optimizers in Deep Learning: When you start learning deep learning, one term repeatedly appears in every tutorial, book, or lecture: optimizers in deep learning. Many students feel confused at first and often ask, “Why do we even need optimizers?”
Someone once said, “A model learns only as well as the optimizer guides it.” This is true, because without the right optimization method, even the best model will not learn properly. In this blog, you will understand what is optimizer in deep learning, why it is used, the types, and how the Adam optimizer in deep learning and SGD optimizer in deep learning work.
The language is simple, the explanations are clear, and the flow is natural.
Let us begin by asking you a basic question…
What Is Optimizers in Deep Learning?
If you want to understand deep learning, start with a simple question: What is optimizer in deep learning? An optimizer is a method that helps your neural network learn by updating the weights during training.
In simple words:
An optimizer tries to reduce the error between predicted output and actual output.
Think of a student preparing for exams. He studies, checks mistakes, corrects them, and improves. Similarly, an optimizer updates the model repeatedly so that the overall error reduces. You will see the phrase use of optimizer in deep learning many times because this is the core of training. Without an optimizer, a model will not improve, even after thousands of samples.
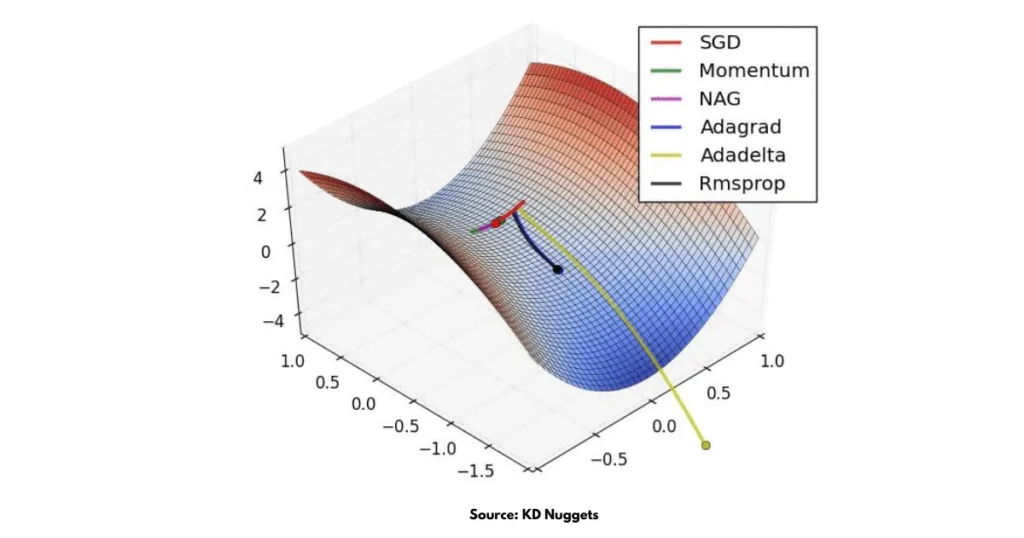
Why Is the Use of Optimizer in Deep Learning So Important?
Let us ask a question: If a model cannot adjust its mistakes, how will it learn? This is exactly why the use of optimizer in deep learning becomes very important. Here are some simple reasons:
- It controls how fast or slow the model learns.
- It updates weights to reduce loss.
- It helps the model reach the best possible accuracy.
- Different tasks require different optimizers.
- Better optimizers lead to faster results.
A popular quote in machine learning says, “Good optimization speeds up the path to good predictions.” This shows why choosing the right optimizer directly affects the model’s performance.
Types of Optimizers in Deep Learning
Now that you know what is optimizer in deep learning, let us look at the types of optimizers. There are many optimizers, but in deep learning, a few are used more commonly:
- SGD (Stochastic Gradient Descent)
- Momentum
- Adam
- RMSProp
- Adagrad
All these come under the broad category of types of optimizers in deep learning, and each has its own strengths. But two optimizers are used almost everywhere:
- SGD optimizer in deep learning
- Adam optimizer in deep learning
We will understand both in detail.
SGD Optimizer in Deep Learning
The SGD optimizer in deep learning is one of the earliest and simplest optimization algorithms. It works by updating model weights one sample at a time. You might wonder, Why does SGD remain popular even today?
Here are some reasons:
- It is simple and easy to implement.
- It works well for large datasets.
- It is used in many research papers.
- It forms the base idea for many advanced optimizers.
Some data scientists say, “If your model is not learning well, try SGD once.” This is because the SGD optimizer in deep learning forces the model to learn directly from raw samples, which sometimes improves accuracy. The use of optimizer in deep learning becomes clearer when you see how SGD slowly reduces loss step-by-step.

Adam Optimizer in Deep Learning
ADAM stands for Adaptive Moment Estimation. It is called this because:
- Adaptive: It adjusts the learning rate automatically.
- Moment: It uses the first moment (mean) and second moment (variance) of gradients.
- Estimation: It estimates these moments during training to update weights smoothly.
The Adam optimizer in deep learning is one of the most widely used optimizers today. It combines the advantages of Momentum and RMSProp, making it fast and stable. Here’s why the Adam optimizer in deep learning is so popular:
- It adjusts the learning rate automatically.
- It handles noisy data very well.
- It is great for deep neural networks.
- It reduces training time.
- It performs well in most real-world tasks.
Read More: Adam Optimizer in Deep Learning: Meaning, Working, Benefits & Limitations
If you search online, you will find this statement often mentioned: “Adam is the go-to optimizer for beginners and experts.” This statement comes from multiple research papers and beginner ML courses, showing its popularity.
When students ask, what is optimizer in deep learning that trains the fastest? Most teachers reply: “Start with Adam.” This is because Adam improves very smoothly and avoids unnecessary jumps in learning.
How Do Optimizers in Deep Learning Actually Work?
By now, you have seen multiple mentions of optimizers. But what happens behind the scenes?
Here is a simple step-by-step explanation:
- The model makes a prediction.
- Loss is calculated.
- The optimizer calculates how much the weights should change.
- It updates the weights.
- The process repeats until accuracy improves.
This shows the real use of optimizer in deep learning. Without constant weight updates, the model will never learn.
Which Optimizer Should You Choose?
Ask yourself: Do I need speed? Stability? Simplicity?
Here is a quick guide:
- If you want simplicity: choose SGD optimizer in deep learning.
- If you want speed and stability: choose Adam optimizer in deep learning.
- If you have very large data: Adam is usually better.
- If you want strong theoretical foundations: SGD is the classic choice.
Remember, your choice depends on your dataset and the problem you are solving.
Here are a few important takeaways that can help you out:
- Optimizers help your model reduce errors.
- They update weights during training.
- Adam is usually the default option today.
- SGD is simple and trusted.
- Different tasks need different optimizers.
When someone asks you what is optimizer in deep learning, you can confidently explain that it is the engine that drives learning.

On A Final Note…
Optimizers act as the foundation of how neural networks learn. The use of optimizer in deep learning cannot be ignored, because without it, a model simply cannot improve. Whether you choose the SGD optimizer in deep learning, the Adam optimizer in deep learning, or any other method, your goal remains the same: to help your model learn better.
As the saying goes, “Training is a journey, and the optimizer is your guide.”
To succeed in deep learning, start by understanding your optimizer well. It will make your learning powerful, faster, and more accurate.
FAQs
What is optimizer in deep learning?
An optimizer in deep learning is a method that updates model weights to reduce errors and improve accuracy during training.
Why do we use optimizers in deep learning?
We use optimizers to help the model learn from mistakes, reduce loss, and improve performance with each training step.
What are the types?
Common types of optimizers in deep learning include SGD, Momentum, RMSProp, Adagrad, and Adam.
Is Adam optimizer in deep learning better than SGD?
Adam optimizer in deep learning is usually faster and more stable, while SGD is simple and works well for many basic models. The best choice depends on the problem.
Which optimizer is best for beginners?
Adam is often recommended for beginners because it adjusts the learning rate automatically and works well in most cases.