



In machine learning, there are numerous techniques that are designed to enhance the performance of models. The first process to approach this is through ensemble methods, which combine the predictions of multiple models to create a more robust and accurate final model. The two most important techniques are bagging and boosting.
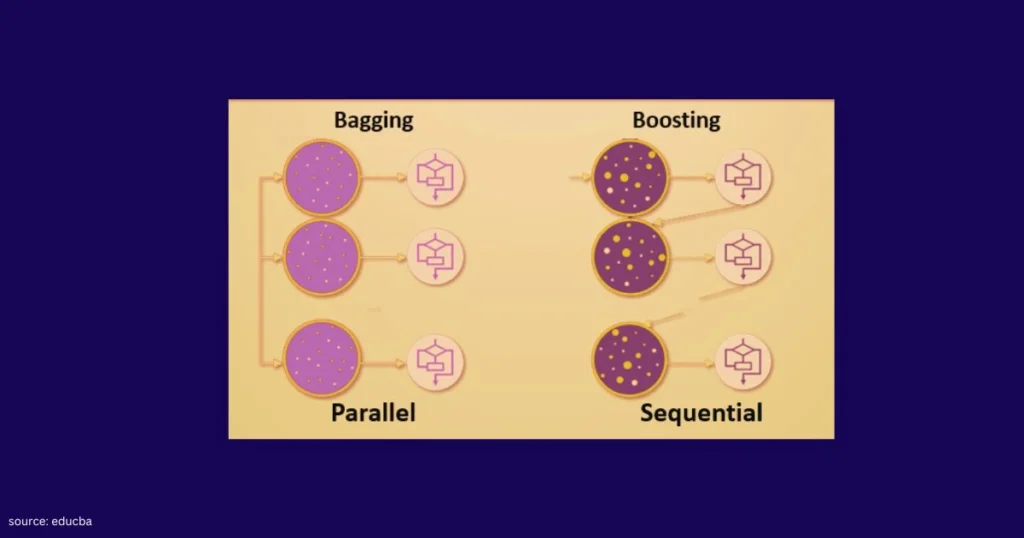
Both methods aim to combine multiple models to achieve better accuracy. Bagging focuses on reducing variance by training various independent models. Whereas, boosting focuses on removing bias by training models sequentially. Every new model corrects the errors of the previous one.
What is Bagging and Boosting in Machine Learning?
Bagging and Boosting in machine learning are two ensemble methods that enhance model performance by combining various weak learners.
Bagging:
Bagging is also a well known learning technique that focuses on removing variance by training multiple models in parallel on separate subsets of data. The term ‘’bagging’’ is classified from the idea of creating various subsets or bags of the training data through a process known as bootstrapping. Bootstrapping is a statistical method that involves creating multiple samples from a single dataset to estimate a model’s accuracy and stability.
Learn all about bagging and boosting in machine learning in this blog by Zenoffi E Learning Labb.
How Bagging Works?
Bagging works by generating various bootstrapped datasets and training an individual model on each of the datasets. The main focus is that by combining predictions from models trained on almost different datasets, the general variance of the model decreases, leading to more accurate and responsible predictions.
Implementation steps of Bagging:
Implementing bagging involves several steps. Here’s a general overview:
- Data Preparation: Prepare the dataset, ensure its properly cleaned and preprocessed. Divide it into a training and a test set.
- Bootstrap Sampling: Randomly sample from the training dataset with replacement to create multiple bootstrap samples. Each bootstrap sample should typically have the same size as the original dataset but contains duplicate records while leaving out some instances.
- Model Training: Training a separate model on each subset of the data.
- Aggregate Prediction: For classification tasks, the final predictions are determined by combining the predictions from all the models.
Benefits of Bagging in Machine Learning
Bagging offers multiple benefits that make it a go-to ensemble learning technique for building robust and accurate machine learning models.
- Reduce Overfitting: By training models on various bootstrap samples and aggregating their predictions, the overfitting leads to poor performance on new, unseen data.
- Improves stability: Changes in the training dataset get less impact on bagged models, making overall models more stable.
- Handles high variability models: It is mainly effective for algorithms like decision trees, which tend to overfit on training data.
- Stability against Outliners: Bagging is more stable in the presence of outliners and noise.
Example of bagging
The Random Forests algorithm is one of the well known implementations of bagging. In Random Forests, numerous decision trees are trained on various bootstrapped samples of the data, and the predictions of the trees are aggregated. This method is mainly effective because it combines the strength of decision trees with stability and robustness of bagging.
Read More: Feature Extraction in Machine Learning: Meaning, Types & Techniques Explained
Boosting:
Bagging is one of the powerful ensemble techniques in machine learning, but unlike bagging, boosting focuses on reducing bias rather than variance. The main idea behind boosting is to give more weight to misclassified instances during the training process, enabling subsequent learners to focus on the mistakes made by their predecessors. Boosting does not rely on bootstrapped subsets of the data.
Continue reading about bagging and boosting in machine learning.
Steps of Boosting:
- Model Initialization: The process starts with training a weak learner on the entire dataset. The first model is not very accurate. This is just the starting point, and the main aim is to keep moving from this step.
- Weight adjustment: The algorithm assigns higher weights to the incorrectly classified examples, emphasizing them in the next round of training. This means that the next model will also give extra priority to those hard examples and try to get them right.
- Model Combination: Every model is added to the ensemble, and its prediction is combined with those of the previous models.

Types of Boosting
Let’s take a look at the three main types of boosting:
- Adaptive boosting or AdaBoost: Adaptive boosting (AdaBoost) was one of the earlier boosting models that has been developed. It adapts and tries to self-correct in every iteration of the boosting methods. The model continues to optimize in a sequential fashion until it yields the strongest predictor.
- Gradient boosting: Gradient boosting is far more performant than AdaBoosting, mainly on complex data. This method attempts to generate accurate results mainly instead of correcting errors throughout the process, like AdaBoost. Gradient boosting helps with both classification and regression-based problems.
- Extreme gradient boosting or XGBoost: This improves gradient boosting for computational speed and scale in several ways. XGBoost uses multiple cores on the CPU, allowing for learning to occur in parallel during training.
Challenges of boosting
- Risk of Overfitting: This includes challenges because in the instances that it does occur, the model’s predictions can not be generalized well to new datasets.
- Reduction of bias: This approach helps to reduce high bias, commonly seen in shallow decision trees and logistic regression models.
- Computational Efficiency: The sequential training in boosting is hard to scale up. Although methods like XGBoost address some scalability concerns, boosting can still be slower than bagging due to its various parameters.
Benefits of boosting in Machine Learning
There are a number of key benefits and challenges that the boosting method presents when using classification or regression problems. Boosting offers the following major benefits:
- Ease of Implementation: Boosting can be used with several parameter tuning options to improve fitting. These boosting algorithms don’t need any data preprocessing, and they have built-in routines to handle missing data.
- Reduction of bias: Boosting algorithms combine multiple weak learners in a sequential method, which iteratively improves upon observations. This approach helps to reduce high bias, which is common in machine learning models.
- Computational efficiency: Boosting algorithms prioritize features that increase predictive accuracy during training. It helps to reduce dimensionality as well as increase computational efficiency.
Example of boosting:
The AdaBoost algorithm, short for Adaptive Boosting, introduced by Freund and Schapire in 1997, revolutionized ensemble modeling. Since its inception, AdaBoost has become a largely accepted technique for addressing binary classification challenges. This powerful algorithm enhances prediction accuracy by transforming a multitude of weak learners into robust, strong learners.

Similarities between Bagging and Boosting
Bagging and Boosting, both being the commonly used methods, they share several similarities of being classified as ensemble methods. Some of the similarities are:
- Both are ensemble method
- Both improves model performance
- Both use base learners
- Both are versatile
When to use Bagging and Boosting
When the model has high variance and low bias, bagging is used. Likewise, when the model has low variance and high bias, boosting is considered the right approach. Bagging and boosting both work for homogeneous weak learners.
Difference between Bagging and Boosting
Both Bagging and Boosting are two different techniques that use various models to reduce mistakes and optimize the model. Here are the differences of bagging and boosting in machine learning.
| Bagging | Boosting |
| The bagging technique combines multiple models trained on different subsets of data. | Boosting skill up the model sequentially, by focusing on the error made by the previous model. |
| Parallel training of models on varied data samples increases diversity | Sequential training allows each model to learn from the previous model’s errors. |
| Utilizes bootstrapping to create multiple subsets of the training data, allowing for variations in the training sets for each base learner. | Assigns weights to instances in the training set, with higher weights given to misclassified instances to guide subsequent learners. |
| All base learners mainly have equal weight when making the final prediction. | Assigns different weights to each base learner based on its performance, giving more influence to learners that perform well on challenging instances. |
| Suitable for reducing overfitting in high variance models (e.g., Random Forset) | Suitable for tasks that need improving model accuracy on complex datasets (e.g., XGBoost, AdaBoost) |
| Random Forest, Bagging Classifier | AdaBoost, Gradient Boosting Machines (GBM), XGBoost, LightGBM |
Additionally, while bagging is relatively simple and easy to resemble, boosting is much more complex because of its sequential nature and may be more liable to overfitting if not properly controlled.
Conclusion:
Bagging and boosting in machine learning are powerful ensemble learning methods that address different aspects of model performance. Bagging is a powerful and simple ensemble method that strengthens model performance by lowering variation, enhancing generalization, and increasing resilience.
On the other hand, boosting is a technique that involves training multiple models sequentially, unlike bagging, boosting focuses on improving the model’s accuracy by adjusting the weights of the training data. Understanding the variation of bagging and boosting provides practitioners with valuable tools to increase the performance of machine learning models across diverse applications. Additionally, understanding the nuances of bagging and boosting in machine learning offers practitioners with valuable tools to enhance the achievement of machine learning models across multiple applications.