



Bagging and Boosting in Machine: In the world of machine learning, no single model works perfectly in every situation. Often, an individual model, also called a weak learner, struggles with bias or variance. That’s where ensemble techniques like bagging and boosting in machine learning step in.
Think of it like this: imagine asking one student to solve a tough math problem. Chances are they’ll make mistakes. But if you ask 100 students and combine their answers smartly, you’re likely to get the right solution. That’s what bagging and boosting do, they combine multiple models to make stronger predictions.
A famous quote by Leo Breiman, the statistician who introduced bagging, goes:
“Bagging is a way of improving the stability and accuracy of machine learning algorithms.”
With that thought in mind, let’s start by answering the fundamental question, what is bagging and boosting in machine learning?

What is Bagging and Boosting in Machine Learning?
Both bagging and boosting are ensemble methods, but their philosophies differ.
- Bagging (Bootstrap Aggregating):
Bagging trains multiple models in parallel using different subsets of the training data created through bootstrapping (sampling with replacement). Each model gives a prediction, and the results are averaged (for regression) or voted upon (for classification). Random Forest is the most popular bagging algorithm. - Boosting:
Boosting, on the other hand, trains models sequentially. Each new model focuses on fixing the errors made by the previous model. Over time, the ensemble becomes stronger. Famous boosting algorithms include AdaBoost, Gradient Boosting, and XGBoost.
So, while bagging reduces variance by averaging, boosting reduces bias by learning from mistakes step by step.
Now let’s see how they behave with classifiers.
Bagging and Boosting of Classifiers
When we talk about bagging and boosting of classifiers, we are focusing on classification problems like predicting whether an email is spam, or whether a loan applicant will default.
- Bagging with classifiers:
Suppose we’re using decision trees to classify whether a patient has diabetes or not. Bagging will create several random samples of the training data, build separate decision trees, and then take a majority vote of their predictions. This stabilises the outcome and avoids overfitting. - Boosting with classifiers:
With boosting, the first decision tree might misclassify some patients. The next tree will try to fix those mistakes by paying extra attention to the wrongly classified cases. This process continues, so the ensemble gradually gets smarter.
As a result, bagging is like having multiple independent judges vote, while boosting is like one judge learning from the mistakes of another before giving a verdict.
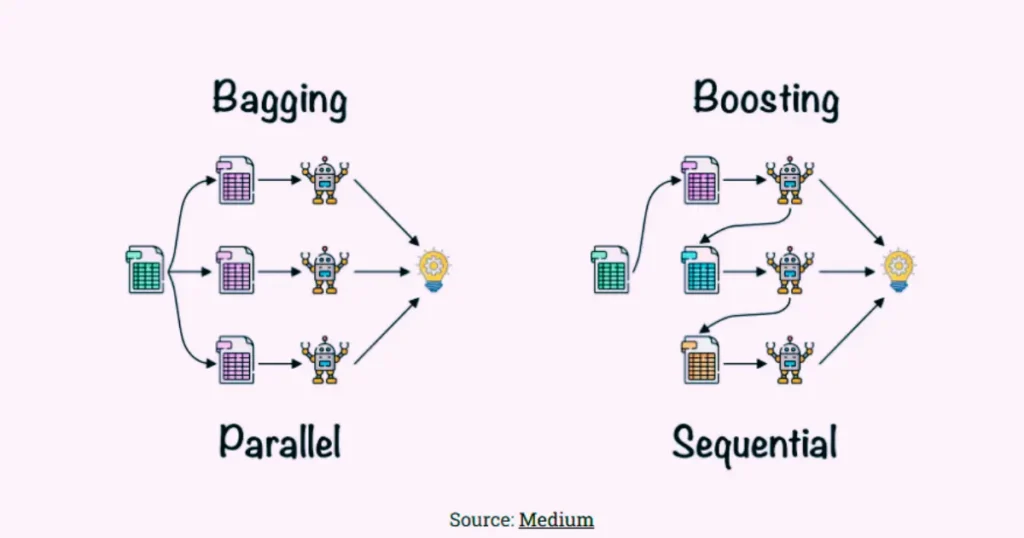
Difference Between Bagging and Boosting
Though both fall under the umbrella of ensemble methods, their differences are worth highlighting.
| Aspect | Bagging | Boosting |
| Approach | Trains models in parallel | Trains models sequentially |
| Focus | Reduces variance | Reduces bias |
| Sampling | Uses bootstrapped samples | Uses entire data but adjusts weights |
| Combination | Averages or takes majority vote | Weighted combination of models |
| Example Algorithm | Random Forest | AdaBoost, Gradient Boosting, XGBoost |
| Best Used For | High variance models | High bias models |
If you’re still wondering, when to use bagging and boosting, keep reading, we’ll get there soon.
Example of Bagging and Boosting
Let’s take two simple real-life scenarios to make this concrete.
- Example of Bagging:
Imagine predicting the price of a house in Bangalore. One decision tree might predict ₹50 lakhs, another ₹52 lakhs, another ₹49 lakhs. Bagging averages these results to give you a reliable estimate. - Example of Boosting:
Now consider fraud detection in banking. The first model may wrongly classify 20% of fraudulent transactions as safe. The second model focuses on correcting those mistakes, and the third further improves on that. By the end, the boosting ensemble becomes highly accurate.
As a quote from Jerome Friedman, who worked extensively on boosting, says:
“Boosting is not just about combining models, it’s about creating a sequence of models that complement each other.”
When to Use Bagging and Boosting?
This is the million-dollar question. When to use bagging and boosting depends on the problem at hand.
- Use bagging when:
- Your model is overfitting the data (high variance).
- You’re working with unstable learners like decision trees.
- Speed is important since models can be trained in parallel.
- Use boosting when:
- Your model has high bias and is underfitting.
- Accuracy is more important than training time.
- You’re working on tasks like ranking, fraud detection, or recommendation systems.
To put it simply:
- Bagging = good for noisy datasets.
- Boosting = good when you need maximum accuracy.
Role of Bagging and Boosting in Data Analytics Training
If you’re pursuing data analytics training, you’ll come across these techniques early on. Both bagging and boosting are considered must-know methods because they’re applied in everything from medical diagnosis to e-commerce recommendation systems.
Here’s why they’re taught in most data analytics training courses:
- They enhance predictive performance.
- They demonstrate how to reduce bias and variance trade-offs.
- They form the backbone of many competitions on platforms like Kaggle.
So, if you’re learning data analytics, make sure you practice building models with Random Forests, AdaBoost, and XGBoost. These aren’t just academic, they’re the tools data scientists use every day.
Know More Here: Data Analytics & Business Analytics with ZELL

On A Final Note…
Bagging and boosting in machine learning may look like twins, but they’re not identical. Bagging is about stability and reducing variance, while boosting is about learning from mistakes and reducing bias. Together, they form the backbone of modern ensemble learning.
When asked when to use bagging and boosting, the answer lies in your dataset—use bagging when your model is too unstable, and boosting when your model is too simple. For learners exploring data analytics training, mastering these techniques is non-negotiable. They’re the kind of concepts that bridge the gap between textbook learning and real-world applications.
As machine learning continues to evolve, one thing remains constant, bagging and boosting are here to stay as the trusted pillars of ensemble learning.
FAQs on Bagging and Boosting in Machine Learning
1. What is bagging and boosting in machine learning in simple words?
Bagging builds many models in parallel and averages their results, while boosting builds models one after the other, each correcting the mistakes of the previous one.
2. What’s the main difference between bagging and boosting?
Bagging reduces variance, boosting reduces bias. Bagging is parallel, boosting is sequential.
3. Can bagging and boosting be used together?
Yes. Hybrid models combine both techniques, though they are less common in practice.
4. What are applications of bagging and boosting of classifiers?
Bagging is used in weather prediction and image classification, while boosting is used in credit scoring, search ranking, and fraud detection.
5. Is boosting always better than bagging?
Not necessarily. Boosting can overfit noisy data, while bagging provides more stability. The choice depends on your problem.