



Data Preprocessing in Data Mining: Raw data is rarely perfect. It often contains missing values, redundant entries, outliers, or inconsistencies that can mislead data mining algorithms. For instance, if a healthcare dataset has incorrect patient ages or duplicate records, the insights derived from it could be dangerous for decision-making.
That’s why data preprocessing in data mining is not a luxury, it’s a necessity. Preprocessing takes messy, raw datasets and transforms them into a structured and usable format.
Think about it like preparing vegetables before cooking a meal. Without washing, peeling, and chopping, even the best recipe won’t work. Similarly, without preprocessing, even the most powerful data mining techniques fail.
As data scientists often say, “Better data beats fancier algorithms.”
In this blog, we’ll tell you all about the world of data preprocessing in data mining. We’ll begin by understanding what data preprocessing in data mining really means and why it’s such an essential step before analysis. From there, we’ll explore the need of data preprocessing in data mining by looking at issues like missing values, noise, and inconsistencies. We’ll then move on to the major tasks and steps in data preprocessing and more…
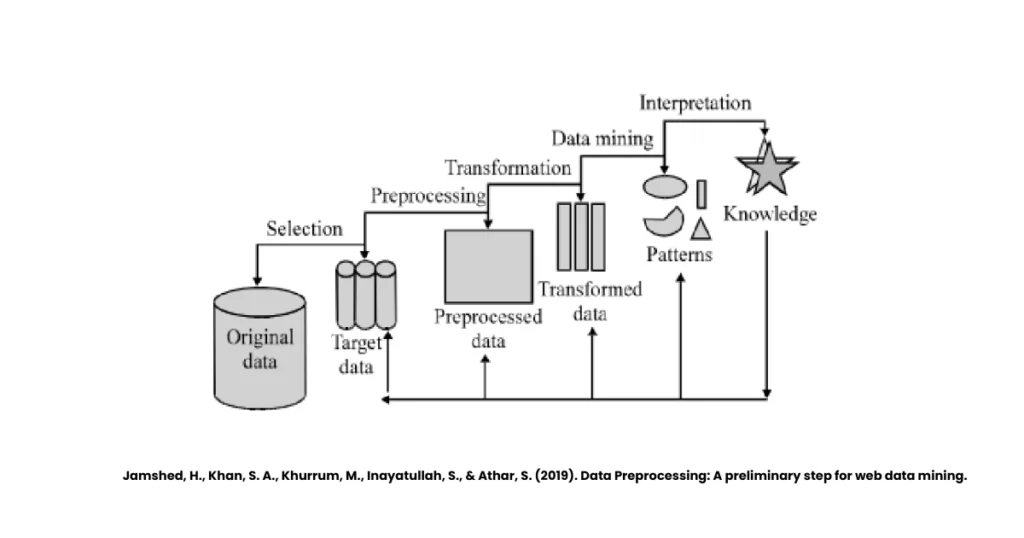
What Is Data Preprocessing in Data Mining?
It’s the process of cleaning, transforming, and organising raw data before feeding it into mining algorithms. In other words, it prepares the “raw material” so that the final “product” (insights) is accurate and useful.
Data preprocessing involves tasks like:
- Identifying missing or incomplete data.
- Standardising formats (e.g., date formats or units of measurement).
- Removing duplicates or redundant records.
- Scaling numeric values for uniform comparison.
- Reducing the size of the dataset to speed up computation.
Example: Imagine an online shopping dataset. If product names are spelled differently (“Mobile,” “Moblie,” “Cell Phone”), analysis will treat them as different products. Preprocessing ensures consistency, so the dataset reflects reality.
So, when someone asks you, “What is data preprocessing in data mining?” the easiest answer is: It is the step that turns raw, messy data into high-quality, structured data that can be trusted for analysis.
Need of Data Preprocessing in Data Mining
Now let’s talk about the need of data preprocessing in data mining.
In real-world scenarios, data collected from multiple sources like websites, surveys, sensors, or transactions is never flawless. It might be:
- Incomplete, missing values like “age” or “income.”
- Noisy, errors due to faulty sensors or human mistakes.
- Inconsistent, different naming conventions, units, or duplicates.
- Unstructured, text, images, or videos without proper labels.
If such data is used directly in mining, the results will be misleading. A marketing company could misidentify target customers, or a hospital could make the wrong prediction about patient health.
That’s why the need of data preprocessing in data mining cannot be ignored. Benefits include:
- Better accuracy: Preprocessed data gives more reliable results.
- Efficiency: Algorithms run faster on reduced and clean datasets.
- Scalability: It makes it easier to handle large datasets.
- Usability: Preprocessed data can be reused across multiple projects.
To put it bluntly, without preprocessing, data mining is like building a house on a weak foundation, it will collapse sooner or later.
Major Tasks in Data Preprocessing
The major tasks in data preprocessing can be grouped into four key activities. Let’s understand each with some detail:
- Data Cleaning
- Deals with missing values, errors, and inconsistencies.
- Techniques: Fill missing data with mean/median, remove outliers, or correct spelling mistakes.
- Example: Replacing missing ages in a customer dataset with the average age of all customers.
- Data Integration
- Combines data from multiple sources into a single, consistent dataset.
- Example: A retail company merging online sales and in-store purchases for a unified view of customers.
- Data Transformation
- Converts data into suitable formats for mining.
- Example: Scaling customer income values into a range between 0 and 1, or encoding categorical values like “Yes/No” into binary (1/0).
- Data Reduction
- Simplifies the dataset by removing irrelevant attributes.
- Techniques: Feature selection, sampling, and dimensionality reduction (like PCA).
- Example: Instead of keeping 100 features in a dataset, keeping only 10 that are most important.
These major tasks in data preprocessing ensure the dataset is consistent, smaller, and easier to analyse, without losing essential meaning.
Steps in Data Preprocessing
When we talk about the steps in data preprocessing, we’re essentially referring to a workflow, a pipeline that every dataset must travel through before being ready for mining. Let’s learn about these steps in detail, and along the way, I’ll describe how you can visualise them like a flowchart in your mind.

The above image shows the basic steps, we have elaborated the steps for your easier understanding.
Think of it as a series of connected boxes:
Raw Data → Data Cleaning → Data Integration → Data Transformation → Data Reduction → Ready for Mining
Now, let’s expand each box.
1. Data Collection
Before any preprocessing starts, data must be collected from relevant sources. These could include databases, spreadsheets, surveys, web scraping, IoT sensors, or transactional systems.
- Challenges: Raw data might be too large, unstructured, or spread across multiple formats.
- Example: A retail company gathers sales data from POS systems, customer feedback surveys, and website logs.
2. Data Cleaning
Once data is collected, it must be cleaned. Cleaning is like washing vegetables before cooking, you’re removing dirt, errors, and anything unnecessary.
- Tasks include:
- Handling missing values (e.g., filling with mean/median, predictive imputation).
- Removing duplicates.
- Detecting outliers and noise.
- Correcting inconsistent data (e.g., “M” vs. “Male”).
- Example: In a student dataset, if some records don’t have exam scores, those blanks can be replaced with the average score of the class.
3. Data Integration
Data often comes from multiple sources. Integration combines them into one consistent dataset.
- Tasks include:
- Schema integration (making sure column names match across datasets).
- Entity resolution (identifying the same individual across systems).
- Handling redundancy (merging overlapping data).
- Example: A hospital may integrate data from patient records, lab tests, and billing systems to create a single profile for each patient.
4. Data Transformation
Once integrated, data must often be reshaped or reformatted. Transformation prepares the dataset for algorithms.
- Techniques include:
- Normalisation: Scaling data into a common range (e.g., incomes scaled 0–1).
- Standardisation: Adjusting values to have a mean of 0 and standard deviation of 1.
- Encoding: Turning categorical data (e.g., “Yes/No”) into numeric values (1/0).
- Aggregation: Combining data fields (e.g., total monthly sales from daily sales).
- Example: If one dataset has income in rupees and another in dollars, transformation converts both into a single unit.
5. Data Reduction
After transformation, datasets may still be too large or complex. Data reduction simplifies them without losing essential meaning.
- Techniques include:
- Feature selection (keeping only the most important variables).
- Sampling (using a smaller representative set).
- Dimensionality reduction (PCA or factor analysis).
- Data compression techniques.
- Example: Instead of analysing 200 variables about a customer, only 10–20 critical ones like age, income, and purchase history may be retained.
6. Final Preparation
This is the last step before mining begins. The dataset is validated to check consistency, accuracy, and usability.
- Tasks include:
- Running statistical summaries.
- Checking for remaining inconsistencies.
- Saving the dataset in the required format (CSV, SQL, etc.).
- Example: Before applying a clustering algorithm, a data scientist ensures that all variables are scaled and there are no missing values left.
Read More: 9 Types of Regression Analysis Explained with Examples
How the Flow Looks in Words
If we were to sketch this in text form:
Raw Data
Alasadi, S. A., & Bhaya, W. S. (2017). Review of data preprocessing techniques in data mining. Journal of Engineering and Applied Sciences, 12(16), 4102-4107.
↓
Data Cleaning → Fix errors, handle missing values, remove duplicates
↓
Data Integration → Merge multiple sources into one
↓
Data Transformation → Scale, encode, standardise, aggregate
↓
Data Reduction → Select features, compress, sample
↓
Final Preparation → Validate and export dataset
↓
Data Mining → Apply algorithms for insights
Each of these steps in data preprocessing builds on the previous one. If cleaning is skipped, integration might bring in duplicates. If transformation is ignored, algorithms may misinterpret data. If reduction is overlooked, computations may take hours or even days.
So, it’s not just a checklist, it’s a chain, and the strength of the chain depends on every single link.
Types of Data Preprocessing in Data Mining
There are different types of data preprocessing in data mining, each designed to address specific issues. Let’s go deeper:
- Data Cleaning: Fixes missing, noisy, or incorrect values.
- Data Normalisation: Scales values into a common range (like 0–1).
- Data Discretisation: Converts continuous attributes into categories. Example: Converting age into ranges (0–18, 19–35, 36–60, 60+).
- Data Integration: Combines multiple data sources into one unified set.
- Data Reduction: Decreases the size of datasets without losing key information.
By applying the right types of data preprocessing in data mining, companies can save time and resources while improving data quality.
Data Preprocessing Techniques in Data Mining
Some popular data preprocessing techniques in data mining include the following:
- Handling Missing Data
- Methods: Deletion, mean substitution, regression imputation.
- Noise Handling
- Methods: Binning, regression, clustering-based detection.
- Scaling and Normalisation
- Min-max scaling, z-score normalisation, decimal scaling.
- Feature Selection
- Selecting only important features to reduce dimensionality.
- Discretisation
- Splitting continuous values into categorical bins.
- Encoding Categorical Data
- Label encoding and one-hot encoding for machine learning readiness.
These data preprocessing techniques in data mining make data uniform, reduce computational cost, and improve accuracy of results.
How Data Preprocessing Works
Let’s take a practical case.
A telecom company collects customer data from multiple sources—calls, internet usage, and billing information. The raw data has:
- Missing fields (like “gender” not entered).
- Different formats of dates (DD/MM/YYYY vs MM-DD-YYYY).
- Outliers (customers with unusually high data usage).
- Duplicate entries.
By applying steps in data preprocessing, the company can:
- Fill missing values with predictive imputation.
- Standardise date formats.
- Detect and remove outliers.
- Merge duplicates into one record.
The cleaned dataset can then be used for mining to predict customer churn or recommend plans.
Challenges in Data Preprocessing
Even though preprocessing is essential, it comes with challenges:
- Time-consuming: Cleaning large datasets takes significant effort.
- Data variety: Handling structured, semi-structured, and unstructured data together is difficult.
- Choosing techniques: Deciding which types of data preprocessing in data mining to use can be tricky.
- Loss of information: Over-cleaning may remove valuable data.
- Automation difficulty: Not all preprocessing can be automated.
These issues make preprocessing one of the most resource-intensive tasks in data mining.

On A Final Note…
To wrap it up, data preprocessing in data mining is the unsung hero behind accurate insights. Without it, mining would be like navigating with a broken compass.
From cleaning and integration to transformation and reduction, every step matters. By applying the right data preprocessing techniques in data mining, businesses can turn raw, unreliable data into a valuable asset.
So, the next time someone asks you, “Why are data mining results not accurate?”, you’ll know where to look, the preprocessing stage.
FAQs
Q1. What is data preprocessing in data mining?
It is the process of cleaning, transforming, and preparing raw data for analysis.
Q2. What are the major tasks in data preprocessing?
They include cleaning, integration, transformation, and reduction.
Q3. Why is there a need of data preprocessing in data mining?
Because raw data is incomplete, noisy, and inconsistent, preprocessing ensures accuracy.
Q4. What are the steps in data preprocessing?
They include collection, cleaning, integration, transformation, reduction, and preparation.
Q5. What are the types of data preprocessing in data mining?
The main types include cleaning, normalisation, discretisation, integration, and reduction.
Q6. What are common data preprocessing techniques in data mining?
They include handling missing values, scaling, discretisation, and feature selection.