



Hadoop Architecture in Big Data: Every day, we create around 2.5 quintillion bytes of data. But storing and analysing this data is not possible with traditional databases. That’s why organisations use Hadoop architecture in big data.
As Doug Cutting, the creator of Hadoop, once explained:
“Hadoop is designed to scale up from single servers to thousands of machines, each offering local computation and storage.”
This makes Hadoop one of the most important technologies for data management. In this extended blog, let’s go deeper into the architecture of Hadoop ecosystem, its components, its role in Industry’s varied industries – let’s go ahead!
What is Hadoop Architecture in Big Data?
Imagine Flipkart during a Big Billion Day sale. Millions of users are browsing products, adding to cart, and making purchases at the same time. Traditional databases cannot handle such massive traffic and data.
But with Hadoop architecture in big data, Flipkart can:
- Store all user clicks, searches, and transactions in HDFS.
- Use MapReduce to process user behaviour.
- Apply analytics to recommend products instantly.
This is how large organisations use Hadoop to turn raw data into business decisions.
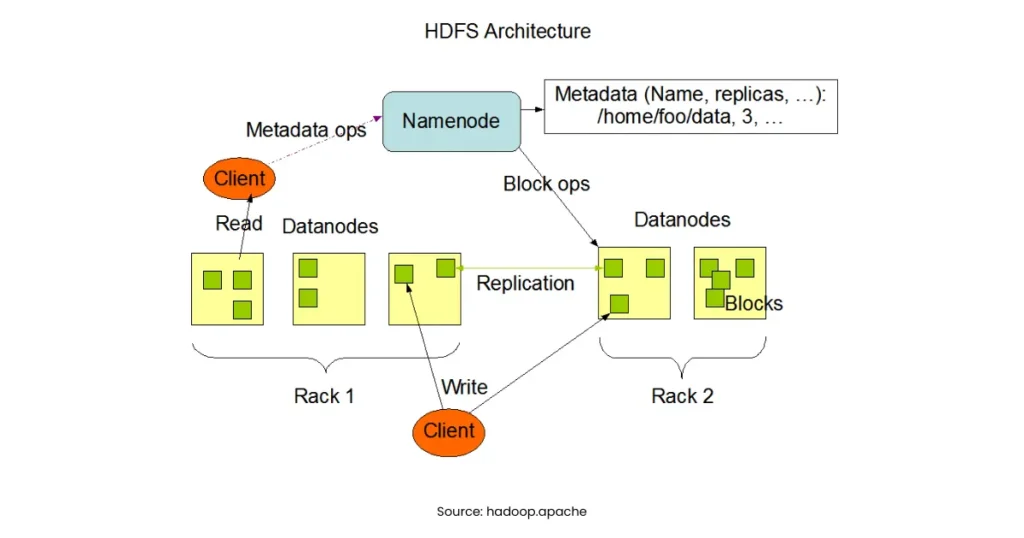
Architecture of Hadoop Ecosystem
The architecture of Hadoop ecosystem is like a team of players in a cricket match. Each player has a role, but the match is won when they work together.
Key layers of the ecosystem:
- Storage Layer (HDFS): Stores massive data in distributed form.
- Processing Layer (MapReduce, YARN): Handles computation and job scheduling.
- Resource Management Layer (YARN): Allocates resources for tasks.
- Data Access Tools (Hive, Pig, HBase, Spark, etc.): Makes it easier for users to query or analyse data.
Together, these layers make the physical architecture of Hadoop strong and scalable.
Core Components of Hadoop
The core components of Hadoop give it strength:
- HDFS: Acts as the warehouse of data.
- MapReduce: The engine that processes jobs in parallel.
- YARN: Works like a manager, assigning jobs to machines.
Think of it as a railway system:
- HDFS is the tracks (storage).
- MapReduce is the train (processing).
- YARN is the station master (resource allocation).
This analogy helps us visualise the master slave architecture in Hadoop as an organised structure.
Master Slave Architecture in Hadoop Explained
The master slave architecture in Hadoop divides tasks efficiently.
- Master Node Responsibilities:
- Runs the NameNode and ResourceManager.
- Maintains metadata of files.
- Monitors cluster health.
- Slave Node Responsibilities:
- Run DataNodes and NodeManagers.
- Store file blocks.
- Execute Map and Reduce tasks.
This structure ensures data is stored safely and processed efficiently. If one node fails, another takes over because of the replication feature in Hadoop distributed file system.
Read More: Data Preprocessing in Data Mining: 6 Steps Explained
Hadoop Distributed File System (HDFS) in Detail
HDFS is the hero of Hadoop architecture in big data. Without it, Hadoop cannot exist.
Main Features:
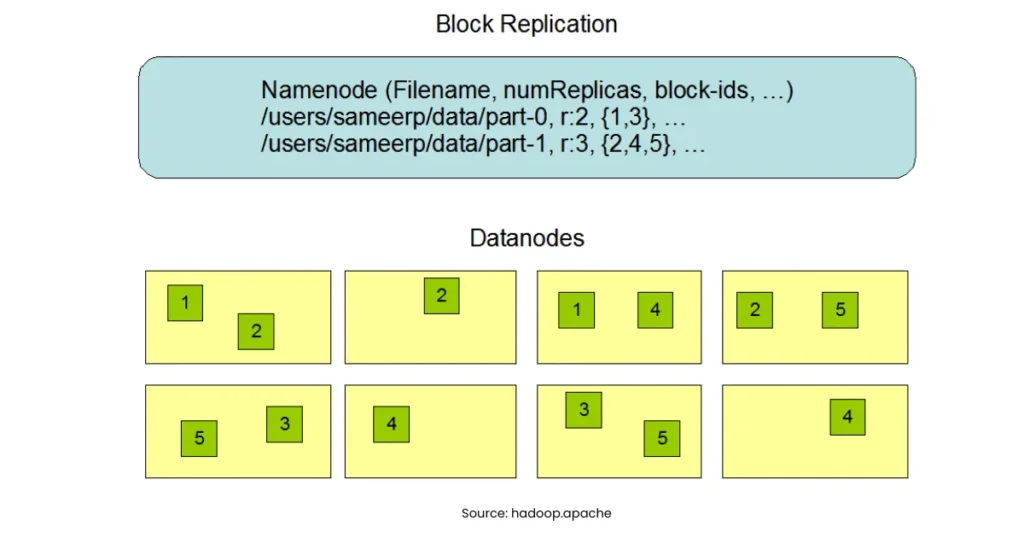
- Block Storage: Splits files into blocks (128 MB by default).
- Replication: Stores copies across different DataNodes (default replication = 3).
- Fault Tolerance: Even if one node fails, data is still available.
- Streaming Access: Optimised for reading huge files.
As per Apache Foundation research, “HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.”
NameNodes in Hadoop
The NameNodes in Hadoop work like a brain:
- Keep track of file directory and block locations.
- Do not store data themselves but maintain metadata.
- Communicate with DataNodes regularly.
If the NameNode fails, the whole HDFS is in trouble. This shows why the secondary namenode in Hadoop is also important.
Secondary Namenode in Hadoop
A common myth is that the secondary namenode in Hadoop is a backup. This is wrong. It is not a backup but a checkpoint server.
- It merges the edit logs with the filesystem image.
- It reduces load on the NameNode.
- If the NameNode fails, the secondary NameNode’s last checkpoint helps in partial recovery.
This distinction is often asked in interviews.
Physical Architecture of Hadoop
The physical architecture of Hadoop refers to the machines and servers.
- Client Machine: Where jobs are submitted.
- Master Machine: Runs NameNode and ResourceManager.
- Slave Machines: Run DataNodes and NodeManagers.
This hardware-level design makes Hadoop clusters flexible. You can start with a few machines and scale up to thousands.
How Hadoop Differs from Traditional Databases
Many wonder – why not use SQL databases instead of Hadoop? The answer lies in scale.
| Features | Traditional Database | Hadoop |
| Data Volume | GB to TB | TB to PB |
| Data Type | Structured only | Structured, semi-structured, unstructured |
| Cost | High | Low (commodity hardware) |
| Scalability | Limited | High |
| Fault Tolerance | Low | High (replication) |
This table shows why Hadoop architecture in big data is better for large-scale analytics.
Advantages of Hadoop Architecture in Big Data
- Open-source and free to use.
- Works on commodity hardware (cost-saving).
- Handles different types of data.
- Provides replication for fault tolerance.
- Scales horizontally by adding more nodes.
Disadvantages of Hadoop
- Not great for small datasets.
- Batch-oriented; not real-time.
- Requires skilled professionals to manage.
- Security features are still evolving.
How Indian Companies Use Hadoop
- Banks in India use Hadoop to analyse customer transactions for fraud detection.
- E-commerce companies like Flipkart and Amazon India use it for recommendation engines.
- Healthcare institutions use Hadoop for analysing patient data and electronic health records.
- Telecom companies use Hadoop to process call data records.
This shows how Hadoop architecture in big data supports Indian industries.

On A Final Note…
The Hadoop architecture in big data continues to be one of the most reliable and scalable frameworks for handling massive datasets. Its architecture of Hadoop ecosystem, core components of Hadoop, master slave architecture in Hadoop, and strong Hadoop distributed file system make it a trusted choice for industries worldwide.
Whether it is the namenodes in Hadoop, the secondary namenode in Hadoop, or the physical architecture of Hadoop, every part plays a role in making big data useful.
As experts often say, “Without Hadoop, the big data revolution would not have been possible.”
Frequently Asked Questions
Q1: What are the core components of Hadoop?
A: HDFS, MapReduce, and YARN are the core components of Hadoop.
Q2: What is the master slave architecture in Hadoop?
A: It divides work between master nodes (managing) and slave nodes (processing and storing data).
Q3: What is the role of Name nodes in Hadoop?
A: They manage metadata and track file block locations.
Q4: What is the function of the secondary namenode in Hadoop?
A: It helps the NameNode with checkpointing, not backup.
Q5: What is the physical architecture of Hadoop?
A: It consists of client machines, master machines, and slave machines forming a cluster.