



Maximum likelihood estimation in machine learning forms the backbone of how models learn from data by finding parameters that make observations most probable. This method powers many algorithms you encounter daily, from predicting customer behaviour in Indian e-commerce to analysing healthcare data in tech hubs.
In this blog, we break it down step by step for anyone starting out. This blog covers what is maximum likelihood estimation in depth, followed by the maximum likelihood estimation formula presented as clear equation images for easy reference. The blog then examines specific cases such as maximum likelihood estimation for Poisson distribution and maximum likelihood estimation exponential distribution, complete with derivations and more…
Read on…
What is Maximum Likelihood Estimation?
What is maximum likelihood estimation? At its heart, it represents a statistical method designed to estimate the parameters of a probability distribution by maximising a likelihood function that measures how well those parameters explain the observed data. Picture a scenario where you analyse rainfall data from Kerala monsoons: MLE determines the rate parameter that best matches recorded amounts, treating data as the fixed truth while adjusting model assumptions. https://www.researchgate.net/publication/228440352_An_Introduction_to_Maximum_Likelihood_Estimation_and_Information_Geometry
Ronald Fisher, the pioneer behind this in the 1920s, described it as “the method which gives mathematically the most powerful test” for hypotheses, a view echoed in modern statistics texts. Unlike moment matching which equates sample moments to theoretical ones, MLE directly optimises probability, making it more precise for complex models.
Key advantages include:
- Adaptability to various data types, from discrete events like app downloads to continuous variables like stock prices.
- Foundation for supervised learning where labels guide parameter tuning.
- Handles multivariate cases, vital for India’s big data challenges in telecom or finance.
Ask yourself: If your dataset shows outliers, does MLE still perform? It does, but with caveats we discuss later. In machine learning pipelines, libraries like scikit-learn embed MLE implicitly, powering classifiers used by startups in Hyderabad’s tech parks.
This method gained traction in India through courses at IITs, where students apply it to local problems like traffic flow prediction in Delhi.
The Maximum Likelihood Estimation Formula
The maximum likelihood estimation formula defines the estimator as the value of θ that maximises the likelihood function based on observed data. For independent observations x₁ through xₙ from a distribution f(x|θ), it takes the form shown below.
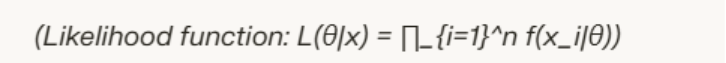
Direct maximisation of products becomes cumbersome with large datasets, so practitioners take the natural logarithm to create the log-likelihood.
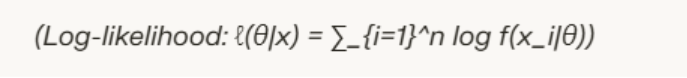
Maximising ℓ(θ) yields the same result as L(θ) since the log function increases monotonically. To solve, compute the partial derivative with respect to θ, set it to zero, and verify the second derivative is negative for a maximum.
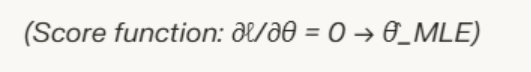
In code, optimisation routines minimise the negative log-likelihood using gradient descent, a staple in TensorFlow or PyTorch. For Indian developers, this translates to faster model training on cloud platforms like AWS Mumbai region.
Why focus on logs? They convert multiplications to sums, stabilise numerical computations, and simplify derivatives, essential for high-dimensional parameters in deep learning.
Common challenges include assuming independence; when violated, use adjusted forms like for time series.
Step-by-Step Derivation
Follow this structured derivation to compute MLE for any distribution.

As per statistical theory, “MLE achieves the highest possible accuracy asymptotically,” per Cramér’s work in the 1940s. In practice, Indian researchers at IISc Bengaluru use this for genomic data analysis.
Maximum Likelihood Estimation for Poisson Distribution
Maximum likelihood estimation for Poisson distribution proves ideal for count data such as daily COVID cases in a city or transaction volumes in Paytm.

Applications:
- Fraud detection: Model rare events per hour.
- Queueing theory: Customer arrivals at IRCTC booking.
- GLM extensions in R for overdispersion handling.
Maximum Likelihood Estimation Exponential Distribution
Maximum likelihood estimation exponential distribution fits lifetimes, service times, or inter-arrival gaps, relevant for India’s renewable energy sector analysing panel failures.

Maximum Likelihood Estimation Example: Coin Flips and Logistic
Start with a basic maximum likelihood estimation example: 10 flips, 7 heads. Bernoulli model.

On A Final Note…
Maximum likelihood estimation in machine learning delivers a robust framework for parameter learning, from basic distributions to advanced neural architectures. Experiment with datasets from UCI repository to solidify skills, after all the path to expertise lies in practice.
FAQs
What is maximum likelihood estimation in simple terms?
A way to pick model parameters that make your data most likely, like estimating rainfall rate from monsoon logs.
What is the maximum likelihood estimation formula?
Maximise ∑ log f(x_i|θ) for independent data.