



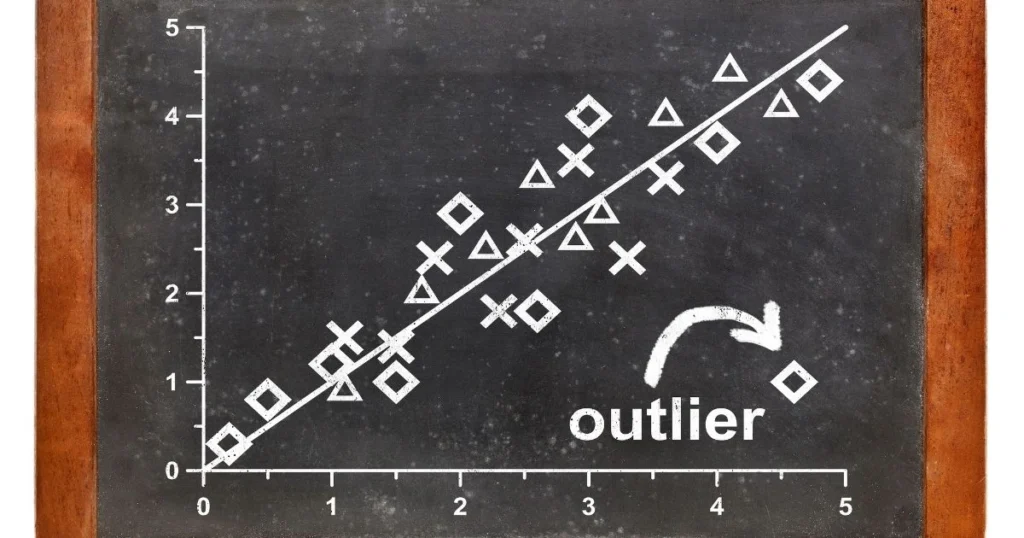
Outlier Detection in Machine Learning: Imagine you’re analysing customer data for an e-commerce platform. Most people shop within a normal range, say ₹1000 to ₹10,000 per order. But suddenly, you spot one user who’s placed a ₹1.5 lakh order, five times in a single day. Should you ignore it? Flag it? Investigate it?
That unusual pattern is what we call an outlier, and finding such anomalies is one of the most important, yet often overlooked, steps in machine learning.
In the world of data, not everything follows the rules. While most observations cluster around typical values, some data points behave differently. These outliers may indicate errors, fraud, or even valuable hidden trends. If left untreated, they can heavily distort your model results. That’s where outlier detection in machine learning comes in.
What Is Outlier in Machine Learning?
So, as you could be thinking – what is outlier in machine learning? It’s a data point that deviates significantly from other observations. It lies far from the mean or follows a pattern that’s noticeably different from the rest of the dataset.
Imagine a customer who usually spends ₹5000 a month suddenly spending ₹1 lakh. That’s an outlier and could indicate fraud, a festival season, or an error in entry.
Outliers are not always bad. They can either be:
- Noise that needs to be removed
- Or signals that deserve attention
The challenge is knowing the difference, and that’s where machine learning outlier detection comes into play.
Why Is Outlier Detection Important?
Let’s understand why outlier detection in machine learning is worth your time and effort:
1. Protect Model Accuracy
Machine learning models assume data is clean and follows certain statistical norms. Outliers can distort those norms, leading to poor performance.
2. Better Business Decisions
Averages and trends built on skewed data can mislead decision-makers. If your average sales per user is off because of one unusually large transaction, you’ll get the wrong picture.
3. Catch the Unexpected
In industries like finance, healthcare, and manufacturing, outliers can point to fraud, defects, or health risks. So, outlier detection isn’t just statistical, it’s practical.
Whether you’re doing fraud detection or user behaviour analysis, spotting the outliers early can make or break your strategy.
Types of Outlier Detection Methods
Let’s dive into the types of outlier detection used in machine learning. These methods are generally grouped into three categories based on how they work.
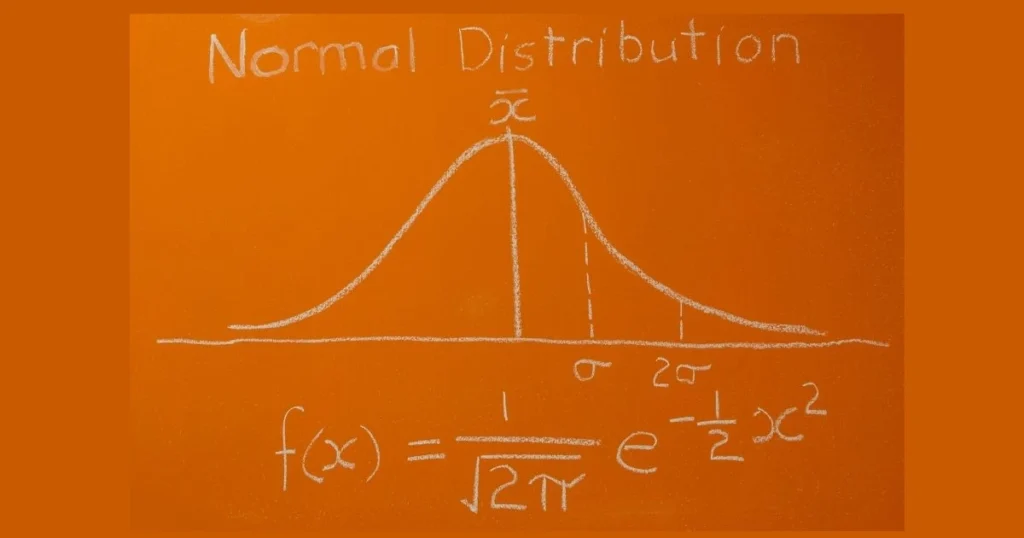
1. Statistical Methods
These work under the assumption that data follows a specific distribution (like Gaussian/normal distribution).
- Z-Score: Measures how far a point is from the mean in terms of standard deviation. Typically, values beyond ±3 are treated as outliers.
- IQR (Interquartile Range): Identifies outliers by looking at values outside Q1 – 1.5IQR and Q3 + 1.5IQR.
These are best for univariate analysis but might miss hidden outliers in multivariate data.
2. Proximity-Based Methods
These look at how far a data point lies from its neighbours.
- KNN-Based Detection: Points that have large distances from their k-nearest neighbours are flagged.
- DBSCAN: Clusters dense regions and marks points in sparse regions as noise or outliers.
3. Clustering-Based Approaches
These are more advanced and don’t require any distributional assumptions.
- Isolation Forest: Builds random trees to isolate anomalies. The fewer splits it takes to isolate a data point, the more likely it is an outlier.
- One-Class SVM: Learns a decision function to classify new data as similar or different from the training set.
These models can be scaled to larger and complex datasets, especially for outlier detection multiple features.

Outlier Detection with Multiple Features
Let’s take a deeper look at outlier detection multiple features. Real datasets usually contain more than one variable, customer age, location, spending, device type, etc.
Identifying outliers in each variable separately is not enough. You must also look at combinations. For instance:
- A purchase at 2 AM might be normal.
- Buying 10 items might be normal.
- But buying 10 expensive items at 2 AM from a new device? That’s likely an outlier.
Multivariate techniques like Mahalanobis Distance, PCA-based outlier detection, and autoencoders help in such cases.
How to Detect and Handle Outliers?
Detecting and managing outliers isn’t just about running a method, it’s about understanding what the data means. Here’s how to go about it:
Step 1: Detecting Outliers
- Visual Methods: Use boxplots, histograms, or scatterplots.
- Statistical Methods: Apply Z-score, IQR, or log transformations.
- Model-Based Methods: Try Isolation Forests, clustering, or autoencoders.
- Domain Knowledge: Know the business rules. What seems odd in one context might be normal in another.
Step 2: Handling Outliers
- Remove Outliers: If they’re errors or unimportant.
- Transform the Data: Use log/sqrt transformations to normalise.
- Impute with Caps/Floors: Replace extreme values with quantile thresholds.
- Use Robust Algorithms: Algorithms like Random Forest or XGBoost handle outliers better than linear models.
So, how to detect and handle outliers depends on the context and the business goal. Removing a fraud transaction in a banking system may hide valuable insight, while in a retail dataset, it might just be an entry error.
Applications of Outlier Detection
Outlier detection isn’t limited to theoretical models. Here are industries where it plays a vital role:
- Finance: Detecting fraud or money laundering
- Healthcare: Flagging abnormal test results or vitals
- Retail: Finding unusual customer behaviour or fake reviews
- Manufacturing: Early detection of machine breakdown or faulty units
- Digital Marketing: Spotting bot traffic, fake clicks, or inflated campaign stats
The applications are wide, and the stakes are high.
More Examples
Let’s walk through a few scenarios:
Case 1: Retail Business
A retailer sees an unusually high number of returns from one region. Is it a system error or customer behaviour? Outlier detection helps isolate the issue.
Case 2: Hospital Emergency Data
One patient record shows abnormally high oxygen level. An error? Or a medical emergency? Data-driven detection backed by human interpretation is the key.
Case 3: Online Learning Platform
A sudden spike in login attempts from one IP address, is it enthusiasm or a security breach? Here too, identifying anomalies early can save you time and cost.
These examples underline that outliers in machine learning aren’t just numbers, they’re often warning signs or untapped insights.
Here’s a quick summary:
- Outlier detection in machine learning is essential for model performance and business insights.
- Outliers are data points that deviate from expected patterns.
- Use statistical, distance-based, and ML models to detect anomalies.
- Handling outliers varies: remove, transform, or use robust models.
- Outlier detection multiple features require multivariate analysis techniques.
- Learn practical application through Zenoffi’s data science and data analytics training.
On A Final Note…
Clean data doesn’t happen by chance. It’s shaped by understanding, curiosity, and smart techniques like outlier detection in machine learning. If you’re serious about building useful models, start by identifying what doesn’t belong.
Sometimes, the most valuable insights lie in the unusual. So, the next time your model fails, ask, could it be the outliers?
Take your data skills to the next level with Zenoffi E-Learning Labb’s project-based programs. Because it’s not just about handling data, it’s about listening to what data is trying to say.
Frequently Asked Questions
Q1: What is outlier in machine learning?
An outlier is a data point that is significantly different from the rest of the dataset.
Q2: How do you handle outliers in machine learning?
You can remove, cap, transform, or use models that are resilient to outliers.
Q3: What is the best method for outlier detection?
It depends on your dataset. For small datasets, use IQR or Z-score. For complex ones, try Isolation Forest or One-Class SVM.
Q4: Can we detect outliers with multiple features?
Yes. Use Mahalanobis Distance, PCA, or multivariate machine learning methods.