



What Is Confusion Matrix In Machine Learning: Machine learning models are often judged based on their accuracy, but accuracy alone is not always a reliable metric. Imagine a medical test for detecting cancer—if 95 out of 100 people are healthy, a model that predicts everyone as “healthy” would have 95% accuracy but would fail to identify actual cancer patients.
This is where the confusion matrix in ML plays a crucial role. It provides a detailed breakdown of a model’s predictions, highlighting where it gets things right and where it makes errors.
In this blog, we will explore:
- What is confusion matrix in machine learning?
- What is the purpose of confusion matrix in machine learning?
- How to make a confusion matrix?
- Key metrics: accuracy, recall, precision, and sensitivity formulas
- Examples of confusion matrix in real-world applications
By the end of this guide, you’ll have a solid understanding of why we use confusion matrix and how to interpret it effectively.
What is Confusion Matrix in Machine Learning?
A confusion matrix in ML is a performance evaluation tool used for classification models. It is a table that compares the actual values with the predicted values of a model, helping to identify errors in classification.

Understanding the Confusion Matrix Structure
A confusion matrix consists of four main components:
| Actual / Predicted | Positive (Predicted) | Negative (Predicted) |
| Positive (Actual) | True Positive (TP) | False Negative (FN) |
| Negative (Actual) | False Positive (FP) | True Negative (TN) |
- True Positive (TP): Model correctly predicts the positive class
- False Negative (FN): Model incorrectly predicts negative for a positive case
- False Positive (FP): Model incorrectly predicts positive for a negative case
- True Negative (TN): Model correctly predicts the negative class
For example, in a spam email classifier:
- TP → Email is spam, and the model predicts spam.
- FN → Email is spam, but the model predicts non-spam.
- FP → Email is not spam, but the model predicts spam.
- TN → Email is not spam, and the model predicts non-spam.
What is the Purpose of Confusion Matrix in Machine Learning?
The confusion matrix is used to evaluate the performance of classification models beyond just accuracy. It helps in:
- Identifying model errors – Understand where the model is making mistakes.
- Balancing false positives and false negatives – Crucial for applications like fraud detection and medical diagnosis.
- Measuring key classification metrics – Accuracy, recall, precision, and sensitivity.
- Improving model performance – Helps in model tuning and optimization.
“Accuracy alone can be misleading. A confusion matrix gives a complete picture of a model’s performance.” – Andrew Ng, Machine Learning Expert
How to Make a Confusion Matrix?
Creating a confusion matrix involves the following steps:
1. Train a Classification Model
Develop a machine learning classification model using algorithms like Logistic Regression, Decision Tree, or SVM.
2. Make Predictions on a Test Dataset
Apply the trained model to a dataset and compare predictions with actual values.
3. Construct the Confusion Matrix
Count True Positives, False Negatives, False Positives, and True Negatives to form a matrix.
4. Calculate Performance Metrics
Using the confusion matrix, compute accuracy, recall, precision, and sensitivity formulas to evaluate the model.
Python’s scikit-learn provides an easy way to generate a confusion matrix:

Key Performance Metrics in Confusion Matrix
1. Accuracy Formula in Confusion Matrix
Accuracy is the ratio of correct predictions to the total number of predictions.
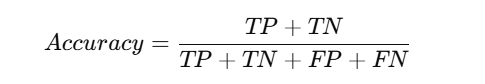
Example: If a model correctly predicts 80 out of 100 cases, the accuracy is 80%.
2. Recall in Confusion Matrix (Sensitivity Formula in Confusion Matrix)
Recall (or Sensitivity) measures how well the model identifies actual positives.
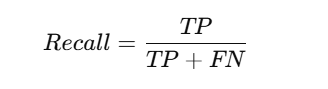
High recall is crucial in medical tests, where missing a positive case can be life-threatening.
3. Precision Formula in Confusion Matrix
Precision measures how many predicted positives are actually correct.
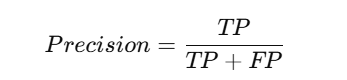
A high precision score is important in spam detection, where false positives (marking non-spam emails as spam) should be minimised.
4. Why Do We Use Confusion Matrix?
- To detect bias in predictions – If FN is high, the model might be underestimating positives.
- To optimise classification models – Helps in adjusting decision thresholds.
- To improve model selection – Enables choosing models based on recall, precision, or F1-score.
Examples of Confusion Matrix in Real-World Applications
1. Medical Diagnosis (Cancer Detection)
A model detecting cancer must have high recall to ensure no positive cases are missed.
2. Fraud Detection in Banking
A fraud detection system must balance false positives and false negatives to avoid blocking genuine transactions.
3. Sentiment Analysis in Digital Marketing
In Ze Learning Labb’s Digital Marketing course, confusion matrices are used to analyse customer sentiment for product reviews.

On A Final Note…
Understanding what is confusion matrix in machine learning is crucial for evaluating classification models. It provides a detailed breakdown of errors, helping to optimise model performance.
By calculating accuracy, recall, precision, and sensitivity formulas, data scientists can make informed decisions about improving models.
For those looking to apply these concepts in real-world scenarios, Ze Learning Labb offers courses in Data Science, Data Analytics, and Digital Marketing to help you master machine learning.