



What Is Gradient Descent In Machine Learning: If you’ve ever wondered, “How do machine learning models learn?”—the answer often lies in an algorithm called gradient descent. Understanding what is gradient descent in machine learning is not just important but essential for anyone working in the fields of data science, artificial intelligence, or deep learning.
Gradient descent is more than just a buzzword; it’s the heart of optimisation in machine learning algorithms. Whether you’re training a neural network or fine-tuning a regression model, this mathematical technique ensures your model makes accurate predictions over time.
Gradient descent is not just a technique, but the foundation of machine learning optimisation.” — Andrew Ng, Founder of DeepLearning.AI
In this blog, we’ll cover:
- What is gradient descent in machine learning?
- How gradient descent works
- Types of gradient descent
- Advantages and disadvantages of gradient descent
- Real-world examples of gradient descent algorithm
Keep reading to know more on what is gradient descent in machine learning….
What is Gradient Descent in Machine Learning?
In simple terms, gradient descent is an optimisation algorithm used to minimise the cost function (or loss function) in a machine learning model. It adjusts the model’s parameters (or weights) to reduce errors between the model’s predictions and actual outcomes.
Think of it as climbing down a hill, step by step, to reach the lowest point, which represents the minimum error. Each step you take depends on the learning rate—a parameter that determines how big each adjustment should be.
In the world of data science, knowing what is gradient descent in machine learning is like knowing the alphabet—it’s foundational for everything that follows.


How Gradient Descent Works: A Step-by-Step Explanation
Understanding how gradient descent works is easier with an analogy. Imagine rolling a ball down a hill:
- Initial position: You start from a random point (random weights).
- Calculate slope: You check which direction leads downward (compute gradient).
- Take a step: Move a little towards the downhill path (update parameters).
- Repeat: Keep going until you reach the lowest point (global minimum).
Here is a detailed explanation for your understanding on how gradient descent works:
- Initialisation
- Start with random values for the model’s parameters (weights and biases).
- These values are adjusted over time to minimise the error.
- Compute the Cost Function
- The cost function tells you how well (or poorly) your model is performing.
- Common cost functions include Mean Squared Error (MSE) for regression tasks.
- Calculate the Gradient (Slope)
- The gradient is the direction and rate of the steepest ascent.
- Since we want to minimise the cost, we move in the opposite direction of the gradient (steepest descent).
- Update the Parameters
- Adjust the parameters using the following update rule:
- Repeat Until Convergence
- Keep updating the parameters until the cost function reaches a minimum value or stops decreasing significantly.
- This means the model has “learned” and found the optimal solution.
In machine learning, this process helps models get better at making predictions by minimising errors during training.
Types of Gradient Descent
There isn’t just one way to roll the ball downhill. Different types of gradient descent suit different problems and datasets. Here are the main types:
- Batch Gradient Descent
- Uses the entire dataset to compute gradients.
- Slower but more stable.
- Best for smaller datasets.
- Stochastic Gradient Descent (SGD)
- Uses a single data point at a time.
- Faster but can be noisy.
- Ideal for large datasets.
- Mini-Batch Gradient Descent
- A mix of both batch and stochastic.
- Uses a small subset (mini-batch) of the dataset.
- Balances speed and accuracy.
Wondering about the difference between gradient descent and stochastic gradient descent? It’s mainly about how much data they process per update.
Advanced Optimisation Techniques
Gradient descent doesn’t always work perfectly on its own, especially with complex datasets. That’s where advanced optimisation strategies come into play:
1. Gradient Descent Optimization
This is the most fundamental optimisation algorithm used in machine learning. It adjusts a model’s parameters (weights) iteratively to minimise the loss function, which measures the difference between predicted and actual outcomes. The basic idea is simple: move in the direction of the steepest descent (the negative gradient) to reduce errors.

2. Momentum-Based Gradient Descent
Standard gradient descent can be slow, especially if the cost function has lots of hills and valleys. Momentum-based gradient descent improves this by adding a fraction of the previous update to the current step. Think of it like pushing a ball downhill—it gains speed (momentum) as it moves.
Benefits:
- Faster convergence
- Reduces oscillations in steep areas
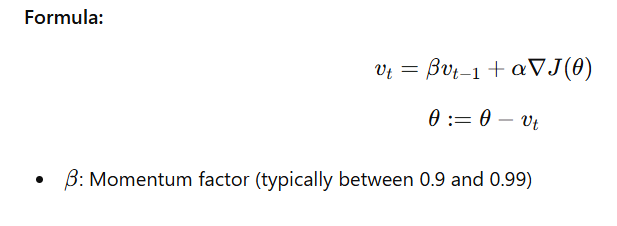
3. Nesterov Accelerated Gradient Descent (NAG)
This is an improvement over standard momentum-based descent. It looks ahead to where the parameters are likely to be in the future and adjusts the step accordingly, allowing for even faster convergence.
Key benefits:
- Reduces overshooting
- Provides better control over step size
- Speeds up training for deep networks
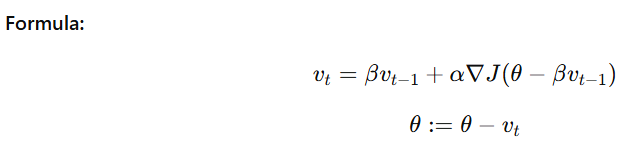
In simple terms, while momentum-based gradient descent relies on past movements, Nesterov Accelerated Gradient Descent takes a proactive approach by considering where the model will likely be next.
Which one should you use?
- Use Gradient Descent Optimization for simple problems or small datasets.
- Opt for Momentum-Based Gradient Descent when dealing with complex loss surfaces.
- Choose Nesterov Accelerated Gradient Descent for deep learning applications where faster convergence is crucial.
What Is the Use of Gradient Descent in Machine Learning?
The primary use of gradient descent algorithm in machine learning is optimisation. Without optimisation, models would fail to learn or improve over time. Here’s why gradient descent is indispensable:
- Reduces prediction errors
- Optimises weights and biases
- Helps models generalise better on unseen data
From basic linear regression to deep learning, almost every modern algorithm relies on gradient descent or its variants.
Example of Gradient Descent Algorithm in Action
Let’s look at a simple example:
Imagine you’re training a model to predict housing prices based on features like area, number of rooms, and location. Initially, your model’s predictions will be way off.
Using gradient descent:
- You calculate the prediction error (cost).
- Adjust the model parameters using the algorithm.
- Gradually, the model’s predictions improve after several iterations.
Result? A more accurate model with minimal prediction errors!

Advantages and Disadvantages of Gradient Descent
Like every algorithm, gradient descent has its pros and cons:
Advantages of Gradient Descent:
- Easy to implement
- Works for various types of machine learning models
- Scales well with large datasets
Disadvantages of Gradient Descent:
- Can get stuck in local minima
- Requires careful tuning of the learning rate
- Slow convergence for large datasets
How to Master Gradient Descent?
If you’re serious about mastering what is gradient descent in machine learning, enrolling in structured courses can be a game-changer. Ze Learning Labb offers industry-relevant courses in:
- Data Science: Explore all about algorithms, including gradient descent.
- Data Analytics: Learn how to optimise insights using machine learning tools.
- Digital Marketing: Understand AI-powered analytics for digital growth.
On A Final Note…
So, what is gradient descent in machine learning really about? At its core, it’s the secret sauce behind most machine learning models. Whether you’re building simple predictive models or deep neural networks, mastering this algorithm is crucial for achieving optimal results.
Ready to take the next step? Check out Ze Learning Labb’s comprehensive courses in Data Science, Data Analytics, and Digital Marketing to level up your skills today!
Your journey to mastering machine learning begins here with Ze Learning Labb—are you ready?