



Outlier Analysis in Data Mining: Not every data fits neatly into a pattern. Sometimes, a few data points behave differently from the rest. They stand out, look strange, or act unexpectedly. These data points are what we call outliers, and discovering them is the focus of outlier analysis in data mining.
Outlier analysis is all about finding those oddballs in your data—numbers that break the trend, don’t follow the crowd, or just feel out of place. These outliers could be signs of mistakes, risks, opportunities, or entirely new insights.
Today, companies rely heavily on data-driven decisions. Ignoring unusual data can mean missing out on important information. Whether you’re a budding data analyst, a digital marketer, or a business student, understanding outlier analysis can give you a competitive edge.
Outlier analysis in data mining is also an important topic taught in Ze Learning Labb’s Data Science and Data Analytics courses—perfect for learners in India and beyond.
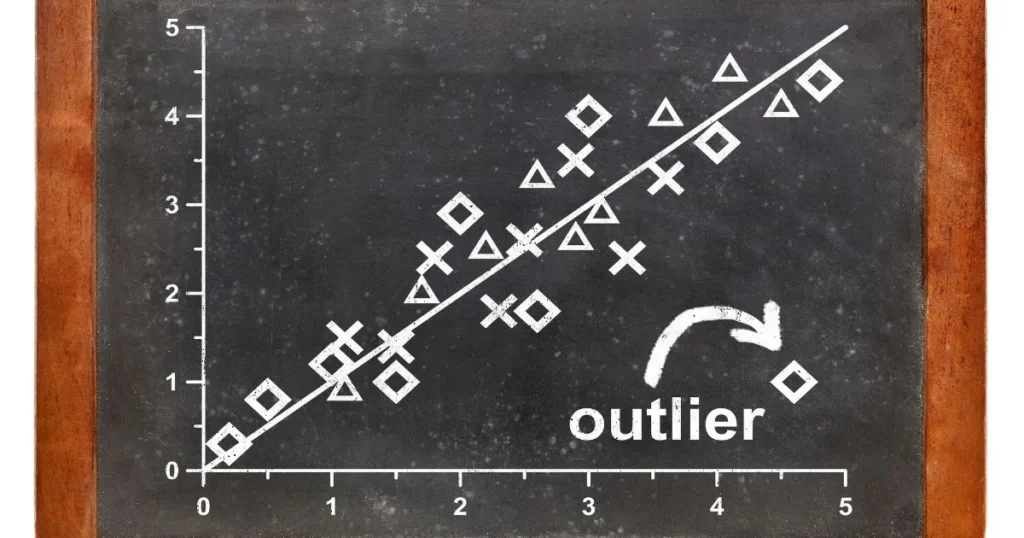
What is Outlier Analysis in Data Mining?
Let’s break it down simply.
To define outlier analysis in data mining, we can say:
“Outlier analysis refers to identifying data points that are significantly different from others in a dataset.”
These points are not errors all the time—they might just reflect rare events or unexpected behaviour. But in any case, they deserve attention.
For example, imagine a temperature sensor logging values from a machine every second. Most of the readings are around 80°C, but suddenly one value jumps to 150°C. That’s an outlier—and it could mean the machine is overheating or malfunctioning.
Outlier analysis helps to:
- Flag suspicious or abnormal behaviour
- Clean noisy or incorrect data
- Discover new, unexpected patterns
- Improve model accuracy in machine learning
So, the next time you look at a dataset, don’t just focus on the average—look out for the weird stuff too. That’s often where the gold lies.
Why Outlier Analysis is Important?
Now, let’s answer a key question: Why outlier analysis is important?
Here’s the truth—outliers can change the course of business decisions. Here are a few reasons why identifying them matters:
1. Spotting fraud and anomalies
In the banking sector, a sudden ₹2 lakh withdrawal from a savings account that usually sees ₹500 withdrawals could mean fraud. Detecting this in time could prevent losses.
2. Improving data quality
Outlier analysis helps identify errors or inconsistencies in data. For example, if an online form logs someone’s age as 500 years, that’s clearly wrong.
3. Early warnings in health & safety
A patient’s sudden spike in heart rate during monitoring could signal an emergency. Spotting this anomaly early can be life-saving.
4. Optimising business processes
Businesses can analyse unusual delays in deliveries or sudden customer dropouts to improve operations.
According to an IBM Data Science report, organisations that applied outlier analysis techniques saw a 23% increase in operational efficiency due to early error detection.
So whether you’re managing customer data, financial transactions, or ad campaign metrics—outlier analysis is a powerful tool to have in your kit.

Types of Outliers in Data Mining
Not all outliers are the same. Based on how they behave, we can classify them into three main types. Understanding these helps choose the right technique for detection. Let’s learn about the types of outlier analysis in data mining…..
1. Global Outliers (Point Anomalies)
These are individual data points that are completely different from the rest.
- Example: A ₹10 lakh transaction in a dataset of ₹200 to ₹3000 transactions.
- Use case: Detecting credit card fraud or extreme stock market spikes.
2. Contextual Outliers
These are data points that may look normal in one context but abnormal in another.
- Example: 25°C may be normal in Bengaluru during winter, but unusual in Delhi.
- Use case: Weather monitoring, sensor data, sales trends.
3. Collective Outliers
A set or group of values that are normal individually but unusual together.
- Example: A group of failed logins in 2 minutes.
- Use case: Cybersecurity, network monitoring, system intrusion detection.
Each of these types of outliers in data mining can reveal different insights depending on the context and application.
Methods Used for Outlier Analysis
There are multiple ways to detect outliers, and each method works better in different situations. Let’s go through the most common methods used for outlier analysis.
1. Statistical methods
These are based on the assumption that data follows a distribution (like a bell curve).
- Outliers are those that lie far from the mean (using z-scores or standard deviation).
- Easy to implement but assumes normal distribution.
- Best for small datasets.
2. Distance-based methods
Here, you calculate the distance between data points.
- If a point is far away from its neighbours, it’s considered an outlier.
- Example: k-Nearest Neighbour (k-NN).
- Works well in datasets with numerical values.
3. Density-based methods
Looks at the density of data points around a given value.
- Points in low-density areas are potential outliers.
- Local Outlier Factor (LOF) is a popular technique.
- Good for datasets with clusters.
4. Clustering-based methods
Uses clustering algorithms like K-means or DBSCAN.
- Points that don’t belong to any cluster or are very far from the cluster centre are flagged as outliers.
5. Machine learning approaches
AI models like Isolation Forest, Autoencoders, and One-Class SVM are used to detect outliers in large datasets.
- Suitable for big data and real-time analytics.
- Used in fraud detection, health monitoring, cybersecurity.
These techniques are hands-on topics taught in the Ze Learning Labb Data Science course, especially in modules focusing on anomaly detection and machine learning.
Outlier Analysis in Data Mining Example
Let’s go through a practical outlier analysis in data mining example to make things even clearer.
Scenario: E-Commerce Return Fraud
An e-commerce platform tracks return requests. Most users return 1-2 items a month. But one account returns 50 items in 7 days, across different categories.
Method used: Distance-based method using k-NN.
Result: The account is flagged for review. Investigation reveals misuse of return policies for cashback rewards.
Outcome: Company prevents further losses and updates their policy rules.
This simple use of outlier analysis in data mining helped the business save money and protect operations.
Applications of Outlier Analysis in Data Mining
Outlier detection is not limited to one industry. It’s used everywhere data is collected.
Here are some applications of outlier analysis in data mining:
- Healthcare: Early detection of unusual symptoms or test values.
- Finance: Identifying money laundering or fraud.
- Retail: Flagging unusual shopping patterns.
- IT and Cybersecurity: Detecting hacking attempts or malware attacks.
- Digital Marketing: Spotting sudden drops or spikes in campaign performance.
In fact, Ze Learning Labb’s Digital Marketing course now includes a module on anomaly detection in ad campaigns, helping marketers fine-tune their targeting and budget strategies.
Challenges in Outlier Analysis
Like every tool, outlier analysis has its challenges:
1. What’s normal anyway?
In many cases, it’s hard to define what ‘normal’ looks like, especially with messy or unstructured data.
2. Noisy data
Not every weird point is useful—some may just be errors or data collection glitches.
3. High dimensions
As the number of variables increases, it becomes harder to find distance-based outliers accurately.
4. Real-time detection
Streaming data and real-time applications require fast and scalable algorithms.
ZELL (Ze Learning Labb) offers research-backed insights and case studies where such challenges are addressed using practical tools and frameworks.
Want to Learn More?
Here are some course suggestions that will help you master this topic:
Ze Learning Labb – Data Science Course
- Dive deep into anomaly detection.
- Hands-on practice with Python.
- Projects on fraud detection, sensor data, and healthcare.
Ze Learning Labb – Data Analytics Program
- Focuses on statistical methods and data visualisation.
- Learn to interpret and clean data effectively.
Ze Learning Labb – Digital Marketing Certification
- Detect campaign anomalies.
- Optimise ad spend and ROI.

Quick Pointers to Remember
- Outliers are unusual data points.
- Outlier Analysis helps identify errors, frauds, and insights.
- Three main types of outliers: Global, Contextual, Collective.
- Common methods: Statistical, Distance, Density, Clustering, Machine Learning.
- Used in industries like finance, healthcare, retail, cybersecurity, and marketing.
Before You Go…
Outliers are not just anomalies—they’re messengers. They tell you what’s different, what needs attention, or what could be your next big opportunity.
Whether you’re a student, marketer, analyst, or just curious about data, outlier analysis in data mining is a skill you’ll want in your toolkit. Interested in learning it the right way? Explore Ze Learning Labb’s courses – and start turning data anomalies into data insights.